算法之排序-快速排序
算法描述
快速排序是一种分治的排序算法。它将一个数组分成两个子数组,将两部分独立的排序。
快速排序和归并排序是互补的:归并排序将数组分成两个子数组分别排序,并将有序的子数组归并以将整个数组排序;而快速排序将数组排序的方式则是当两个子数组都有序时整个数组也就自然有序了。在归并排序中,一个数组被等分为两半;在快速排序中,切分(partition)的位置取决于数组的内容。
特点
它是原地排序(只需要一个很小的辅助栈),且将长度N的数组排序的所需的时间和NlogN成正比。其他排序算法都无法将这两个优点结合起来。
快速排序的内循环比大多数的排序算法都要短小,意味着无论是理论上还是实际上都要更快。
缺点是非常脆弱,实现时要非常小心以避免低劣的性能。
算法之排序-希尔排序
算法描述
希尔排序为了加快速度简单的改进了插入排序,交换不相邻的元素以对数组的局部进行排序,并最终用插入排序将局部有序的数组排序。
希尔排序的思想是使数组中任意间隔为h的元素都是有序的。这样的数组成为h有序数组。在进行排序时,如果h很大,就能将元素移动到很远的地方,为实现更小的h有序创造方便。

特点
希尔排序更高效的原因是它权衡了子数组的规模和有序性。排序之初各个子数组都很短,排序之后的子数组都是部分有序的,这两种情况都很适合插入排序。子数组的部分有序取决于递增序列的选择。
对于中等大小的数组它的运行时间是可以接受的。他的代码量小,不需要额外的内存空间。后面我们会看到更加高效的算法,但是对于很大的N,它们可能只比希尔排序快2倍(可能还达不到),而且更复杂。可以考虑先用希尔排序,然后在考虑是否值得将它替换为更加复杂的排序算法。
代码
使用序列1/2(3的k次方 - 1),从N/3开始递减至1。这个序列成为递增序列。
1 | public class Shell { |
比较
和选择排序和插入排序形成鲜明对比的是,希尔排序也可以用于大型数组。它对任意排序(不一定是随机的)的数组表现也很好。
通过SortCompare可以看到,希尔排序比插入排序要快的多,并且数组越大,优势越大。
算法之排序-选择排序与插入排序的比较
我们将通过以下步骤比较两个算法:
- 实现并调试他们
- 分析他们的基本性质
- 对他们的相对性做出猜想
- 用实验证明我们的猜想
前面两节的算法已经实现了第一步,命题A,命题B,命题C组成了第二步,下面的性质D是第三步,之后的比较两种排序算法的SortCompare类将会完成第四步。
性质D
对于随机排序的无重复主键的数组,插入排序和选择排序的运行时间是平方级别的,两者之比应该是一个较小的常数。
比较两种算法
1 | public class SortCompare { |
等待超时模式
经常遇到这样的场景:调用一个方法时等待一段时间,如果该方法能够在给定的时间段内得到结果,那么结果立刻返回,反之,超时返回默认结果。
前面介绍了等待/通知的经典范式,即加锁、条件循环和处理逻辑3个步骤,而这种范式无法做到超时等待。超时等待的加入,只需要对经典范式做出小改动,改动如下:
假设超时时间是T,那么可以推断出在当前世界now+T之后就会超时。
定义如下变量
- 等待持续时间:remaining = T
- 超时时间: future = now + T
这时只需要wait(remaining)即可,在wait(remaining)返回之后将执行:remaining = future - now。如果remining小于等于0,表示已经超时,直接退出,否则继续执行wait(remaining)
伪代码如下:
1 | //对当前对象加锁 |
超时模式就是在等待/通知模式上添加了超时控制,这使得该模式比原有的范式更具有灵活性,因为即使方法执行时间过长,也不会『永久』阻塞调用者,而是会按照调用者的要求『按时』返回。
Thread.join()的使用
如果一个线程A执行了thread.join()语句,其含义是:当前线程A等待thread线程终止后才从thread.join()返回。线程Thread除了提供join()方法之外,还提供了join(long millis)和join(long millis,int nanos)两个具备超时特性的方法。这两个方法表示,如果线程thread在给定的超时时间里没有终止,那么将会从该超时方法中返回。
例子:
创建10个线程,编号0~9,每个线程调用前一个线程的join()方法,也就是线程0结束了,线程1才能从join()方法中返回,而线程0需要等待main线程结束。
1 | public static void main(String[] args) { |
1 | 0 terminate. |
从上述输出可以看到,每个线程的终止前提是前驱线程的终止,这里涉及到了等待/通知机制(等待前驱线程结束,接收前驱线程结束通知)。
join()方法的逻辑结构同等待/通知经典范式一致,即加锁,循环和处理逻辑3个部分。
算法之排序-插入排序
算法描述
通常人们整理桥牌的方法是一张一张的来,将每一张插入到其他已经有序额牌中的适当位置。在计算机实现中,为了给要插入的元素腾出空间,我们需要将其余所有元素在插入之前都向右移动一位。这种算法叫做插入排序。
与选择排序一样,当前索引左边的所有元素都是有序的,但他们的最终位置还不确定,为了给更小的元素腾出空间,他们可能会被移动。但是当索引到达数组的右端时,数组排序就完成了。
和选择排序不同的是,插入排序所需要的时间取决于输入中元素的初始顺序。例如,对一个很大且其中的元素已经有序(或者接近有序)的数组进行排序将会比随机顺序的数组或是逆序数组进行排序要快的多。
命题B
对于随机排列长度为N且主键不重复的数组,平均情况下插入排序需要 ~ N²/4 次比较以及 ~ N²/4 次交换。最坏情况下需要 ~ N²/2 次比较和 ~ N²/2 次交换,最好情况下需要 N-1次比较和0次交换。
命题C
插入排序需要的交换操作和数组中倒置的数量相同,需要的比较次数大于等于倒置的数量,小于等于倒置的数量加上数组的大小再减一。
特点
插入排序对于部分有序的数组十分高效,也适合小规模数组。
几种典型的部分有序数组:
- 数组中每个元素距离它的最终位置都不远
- 一个有序的大数组接一个小数组
- 数组中只有几个元素的位置不正确
代码
1 | public class Insertion { |
ThreadLocal的使用
ThreadLocal,即线程变量,是一个以ThreadLocal对象为键、任意对象为值的存储结构。
这个结构附带在线程上,也就是说一个线程可以根据一个ThreadLocal对象查询到绑定在这个线程上的一个值。
通过set(T)方法设置一个值,在当前线程下再通过get()方法获取到原先设置的值
例子:
构建了一个常用的Profiler类,具有begin和end两个方法,end()方法返回从begin()方法调用到end()方法调用时的时间差,单位是毫秒。
1 | public class Profiler { |
等待通知机制
等待方遵循原则
- 获取对象的锁
- 如果条件不满足,那么调用对象的wait(),被通知后仍要检查条件
- 条件满足则执行对应的逻辑
伪代码如下:
1 | synchronized( 对象 ) { |
通知方遵循原则
- 获得对象的锁
- 改变条件
- 通知所有等待在对象上的线程
伪代码如下:
1 | synchronized ( 对象 ) { |
代码示例
1 | public class WaitNotify { |
运行结果:
1 | Thread[WaitThread,5,main]flag is true. wait @ 21:35:39 |
安全的终止线程
1、线程中断操作适合用来取消或停止任务
2、利用boolean变量控制需要停止任务并终止该线程
1 | public static void main(String[] args) throws InterruptedException { |
线程的状态
Java线程在运行的周期中可能处于6种不同的状态,在给定的时刻,线程只能处于其中一个状态
| 状态名称 | 说明 |
|---|---|
| NEW | 初始状态,线程被构建,但是还没有调用start()方法 |
| RUNNABLE | 运行状态,Java线程将操作系统中的就绪和运行两种状态笼统的成为『运行中』 |
| BLOCKED | 阻塞状态,表示线程阻塞于锁 |
| WAITING | 等待状态,表示线程进入等待状态,进入该状态表示当前线程需要等待其他线程做出一些特定动作(通知或中断) |
| TIME_WAITING | 超时等待状态,该状态不同于WAITING,它是可以在指定的时间自行返回 |
| TERMINATED | 终止状态,表示当前线程已执行完毕 |

算法之排序-选择排序
算法描述
- 首先,找到数组中最小的元素
- 其次,将它和数组的第一个元素交换位置(如果第一个是最小的,就和自己交换)
- 再次,在剩下的元素中找到最小的元素,将它与第二个元素交换位置。
- 如此往复,直到将整个数组排序
命题A
对于长度为N的数组,选择排序需要大约N²/2次比较和N次交换
特点
运行时间和输入无关。
为了找出最小的元素而扫描一遍数组并不能为下一遍扫描提供什么信息。这种性质在某些情况下是缺点,一个已经有序的数组或者主键全部相等的数组和一个元素随机排列的数组所用的排序时间一样长!
数据移动是最少的。
每次交换都会改变两个元素的位置的值,因此选择排序用了N次交换——交换次数和数组的大小是线性关系。其他任何算法都不具备这个特征(大部分的增长数量级都是线性对数或者平方级别)
代码
1 | public class Selection { |
其中less方法和exchange方法在工具类中,如下:
1 | public class SortUtils { |
算法练习——链表
单链表的创建和删除
1 | import lombok.AllArgsConstructor; |
算法练习——数组
二维数组中的查找
在一个二维数组中,每一行按照从左到右递增顺序排序,每一列都按照从上到下递增的顺序排序。请完成一个函数,输入这样的一个二维数组和一个整数,判断数组中是否含有该整数。
当我们要解决一个复杂的问题时,一个很有效的方法就是从一个具体的问题入手,通过分析简单的例子,试图寻找普遍的规律。
具体的🌰:例如下面的数组就是每行每列递增排序。如果在这个数组中查找到数字7则返回true;如果查找数字5,则返回false。
解决方法:从数组的一个角上选取数字来和要查找的数字做比较。情况会变的简单

1 | public boolean isNumberExist(int rows, int columns, int number) { |
JVM笔记八:Sun JDK监控和故障处理工具
Sun JDK监控和故障处理工具:
| 名称 | 主要作用 |
|---|---|
| jps | JVM Process Status Tool,显示指定系统内所有HotSpot虚拟机进程 |
| jstat | JVM Statistics Monitoring Tool,用于收集HotSpot虚拟机各方面的运行数据 |
| jinfo | Configuration Info for Java,显示虚拟机配置信息 |
| jmap | Memory Map for Java,生成虚拟机的内存转出快照(heapdump)文件 |
| jhat | JVM Heap Dump Browser,用于分析heapdump文件,它会建立一个HTTP/HTML服务器,让用户在浏览器上查看分析结果 |
| jstack | Stack Trace for Java,显示虚拟机的线程快照 |
JVM笔记七:垃圾收集器与内存分配策略——内存分配与回收策略
JVM笔记六:垃圾收集器与内存分配策略——垃圾收集器
基于JDK1.7 Update 14之后的HotSpot虚拟机的垃圾收集器。

两个收集器之间有连线,说明他们可以搭配使用。收集器所处的区域,则表示他是属于新生代收集器还是老生代收集器。
Serial收集器


新生代收集(Minor GC)
下面代码尝试分配3个2MB大小和1个4MB大小的对象
- 运行通过-Xms20M(堆初始大小)、-Xmx20M(堆最大值)、-Xmn10M(新生代值)这3个参数限制了Java堆大小为20MB,不可扩展,其中10MB分配给新生代,剩下的10MB分配给老年代
- -XX:SurvivorRatio=8 决定了新生代中Eden区与一个Survivor区的空间比例为 8:1
- 新生代总可用空间:9216KB(Eden区+1个Survivor区的总容量)
- -XX:+PrintGCDetail,在发生垃圾收集时打印内存回收日志


JVM笔记四:垃圾收集器与内存分配策略——对象
在堆里存放着Java世界中几乎所有的对象实例,垃圾收集器在对堆进行回收前,第一件事情就是要确定这些对象之中哪些还存活着,哪些已经死去(即不可能再被任何途径使用的对象)。
引用计数法
引用计数法(Reference Counting):给对象中添加一个引用计数器,每当有一个地方引用它时,计数器就加1;当引用失效时,计数器就减1;任何时刻计数器为0的对象是不可能被使用的。主流的Java虚拟机里没有使用引用计数法来管理内存,主要原因是它很难解决对象之间的相互循环引用的问题。
1 | /** |
运行结果:
1 | [Full GC (System) [CMS: 0K->423K(63872K), 0.0099285 secs] **6167K->423K**(83008K), [CMS Perm : 4749K->4747K(21248K)], 0.0107293 secs] [Times: user=0.01 sys=0.00, real=0.01 secs] |
6167K->423K(83008K)意味着虚拟机并没有因为这两个对象并相互引用就不回收他们,也从侧面说明虚拟机并不是通过引用计数法来判断对象是否存活的。
JVM笔记三:Java内存区域与内存溢出异常——OutOfMemoryError异常
Java堆溢出
Java堆用于存储对象实例,只要不断地创建对象,并且保证GC Roots到对象之间有可达路径来避免垃圾回收机制清除这些对象,那么在对象数量到达最大的容量限制后就会产生内存溢出异常。
下面代码限制Java堆的大小为20MB,不可扩展(将堆的最小值-Xms参数与最大值-Xmx参数设置为一样即可避免堆自动扩展),通过参数-XX:+HeapDumpOnOutOfMemoryError可以让虚拟机在出现内存溢出时Dump出当前的内存堆转储快照以便事后进行分析。
1 | /** |
运行结果:
1 | java.lang.OutOfMemoryError: Java heap space |
JVM笔记二:Java内存区域与内存溢出异常——HotSpot虚拟机对象探秘
以常用的虚拟机HotSpot和常用的内存区域Java堆为例,深入探讨HotSpot虚拟机在Java堆中对象分配、布局和访问的全过程。
对象的创建

- 虚拟机遇到一条new指令
- 检查这个指令的参数是否能在常量池中定位到一个类的符号引用。并且检查这个符号引用代表的类是否已被加载、解析、初始化过,没有必须先执行相应的类加载过程。
- 指针碰撞:若干Java堆中内存是绝对规整的,所有用过的内存都放在一边,空闲的内存放在另一边,中间放着一个指针作为分界点的指示器,那所分配的内存就仅仅是把那个指针向空闲空间那边挪动一段与对象大小相等的距离。
- 空闲列表:如果java堆中的内存并不是规整的,已使用的内存和空闲的内存相互交错,JVM必须维护一个空闲列表用来记录哪些内存块是可用的,在分配的时候从列表中找到一块足够大的空间划分给对象实例,并更新列表上的记录
- 内存分配完成以后,虚拟机需要将分配到的内存空间都初始化为零值(不包括对象头),确保对象的实例字段在Java代码中可以不赋初始值就直接使用,程序能访问到这些字段的数据类型所对应的零值。
- 接下来,JVM对对象进行必要的设置,例如:这个对象是哪个类的实例、如何才能找到类的元数据信息、对象的哈希值、对象的GC分代年龄等信息。这些信息存放在对象头(Object Header)中。
- 上面的工作完成之后,从JVM的角度,一个新的对象以及产生了。
- 对Java程序来说,对象所有的字段都为零值,所以一般来说,执行new指令之后会接着执行
方法,把对象按照程序员的意愿进行初始化,这样一个真正可用的对象就完全产生出来。

Java NIO FileChannel
Java NIO中的FileChannel是一个连接文件的channel,可以使用它从文件中读取数据或向文件中写入数据。Java NIO的FileChannel是NIO的一个选择相对标准的Java IO API来说。
FileChannel可以设置成非阻塞模式,但是仍然会按照阻塞模式运行。
打开FileChannel
在使用FileChannel时需要先打开它,但是不能直接打开。需要借助InputStream,OutputStream或者是RandomAccessFile。
举个🌰:
1 | RandomAccessFile aFile = new RandomAccessFile("data/nio-data.txt", "rw"); |
从FileChannel读数据
从FileChannel读数据可以调用read()方法。
举个🌰:
1 | ByteBuffer buf = ByteBuffer.allocate(48); |
首先给Buffer分配字节, FileChannel中的数据就是读到Buffer中。
其次,再调用FileChannel.read()方法。从FileChannel中将数据读入buffer。read()的整型返回值告诉我们已经写入Buffer的字节量。如果返回-1,就是读到了文件的结尾。
FileChannel写入数据
Writing data to a FileChannel is done using the FileChannel.write() method, which takes a Buffer as parameter. Here is an example:
1 | String newData = "New String to write to file..." + System.currentTimeMillis(); |
Notice how the FileChannel.write() method is called inside a while-loop. There is no guarantee of how many bytes the write() method writes to the FileChannel. Therefore we repeat the write() call until the Buffer has no further bytes to write.
关闭FileChannel
When you are done using a FileChannel you must close it. Here is how that is done:
1 | channel.close(); |
FileChannel Position
When reading or writing to a FileChannel you do so at a specific position. You can obtain the current position of the FileChannel object by calling the position() method.
You can also set the position of the FileChannel by calling the position(long pos) method.
Here are two examples:
1 | long pos channel.position(); |
If you set the position after the end of the file, and try to read from the channel, you will get -1 - the end-of-file marker.
If you set the position after the end of the file, and write to the channel, the file will be expanded to fit the position and written data. This may result in a “file hole”, where the physical file on the disk has gaps in the written data.
FileChannel Size
The size() method of the FileChannel object returns the file size of the file the channel is connected to. Here is a simple example:
1 | long fileSize = channel.size(); |
FileChannel Truncate
You can truncate a file by calling the FileChannel.truncate() method. When you truncate a file, you cut it off at a given length. Here is an example:
1 | channel.truncate(1024); |
This example truncates the file at 1024 bytes in length.
FileChannel Force
The FileChannel.force() method flushes all unwritten data from the channel to the disk. An operating system may cache data in memory for performance reasons, so you are not guaranteed that data written to the channel is actually written to disk, until you call the force() method.
The force() method takes a boolean as parameter, telling whether the file meta data (permission etc.) should be flushed too.
Here is an example which flushes both data and meta data:
1 | channel.force(true); |
Java NIO Selector
原文:http://tutorials.jenkov.com/java-nio/selectors.html
Selector是Java NIO中用来检查一个或多个NIO通道的,决定哪个通道做好准备进行读写的组件。这样,一个单线程就可以管理多个通道,以便管理多个网络连接。
为何使用Selector?
使用单线程处理多通道的好处就是可以使用更少的线程处理多个通道。实际上可以使用只用一个线程处理多个通道。在操作系统中,线程切换开销很大。每个线程都会占用一些资源(内存)。因此,线程越少越好。
但是,当前操作系统和CPU多任务处理上已经非常好,多线程的开销已经变得很小了。如果一个CPU有多个内核,不使用多任务可能是在浪费CPU能力。不管怎么说,关于那种设计的讨论应该放在另一篇不同的文章中。在这里,只要知道使用Selector能够处理多个通道就足够了。
使用一个Selector处理3个channel的图解如下:

Selector的创建
调用Selector.open()方法创建一个selector。像这样:
1 | Selector selector = Selector.open(); |
Channel注册到Selector上
为了结合Selector使用Channel,首先要将Channel注册到Selector上。通过方法SelectableChannel.register()实现:
1 | channel.configureBlocking(false); |
结合Selector使用时,Channel必须是非阻塞师的。这就意味着,你不能把FileChannel和Selector结合使用,因为FileChannel不能切换到非阻塞模式。Socket Channel确可以很好的结合Selector使用。
register()方法的第二个参数需要注意下。这是个有趣的设置,意思是在通过Selector监听Channel时刚兴趣的事件。可以监听到以下四种事件:
- Connect
- Accept
- Read
- Write
一个channel触发了事件就是意味着该事件已就绪。因此,channel连接服务成功就是Connect就绪。服务socke channel准备接受进入的连接就是Accept就绪。服务socket channel已经准备好了可以读取的数据就是Read就绪。channel准备好可以写入数据就是Write就绪。
这四种事件用SelectionKey的常量表示:
- SelectionKey.OP_CONNECT
- SelectionKey.OP_ACCEPT
- SelectionKey.OP_READ
- SelectionKey.OP_WRITE
如果对多个事件感兴趣,那么可以用“位或”操作符将常量连接起来,像这样:
1 | int interestSet = SelectionKey.OP_READ | SelectionKey.OP_WRITE; |
下面还会继续提到interest集合。
SelectionKey
通过前面示例可以看到,调用register()方法向selector上注册channel时返回SelectionKey对象。这个SelectionKey对象中包含很多有趣的属性。
- interest集合
- ready 集合
- Channel
- Selector
- 附加对象(可选)
下面会描述这些属性。
Interest集合
就像向Selector注册通道一节中所描述的,interest集合是你所选择的感兴趣的事件集合。通过SelectionKey可以读写interest集合。
1 | int interestSet = selectionKey.interestOps(); |
可以看到,使用『位与』操作interest集合和给定的的SelectionKey常量,可以确定某个确定的世界是否在interest集合中。
Ready集合
ready集合是channel已经准备就绪的channel集合。在一次selection以后,可以先获得ready集合。至于selecton,会再下面的章节解释。可以这样获取ready集合:
1 | int readySet = selectionKey.readyOps(); |
可以用像检测interest集合那样的方法,来检测channel中什么事件或操作已经就绪。但是,也可以使用以下四个方法,它们都会返回一个布尔类型:
1 | selectionKey.isAcceptable(); |
Channel + Selector
Accessing the channel + selector from the SelectionKey is trivial. Here is how it’s done:
从SelectionKey中获得channel和selector很简单,像这样就好:
1 | Channel channel = selectionKey.channel(); |
附加对象
可以将一个对象附加到SelectionKey上。这是个识别给定的channel的简便方法,还可以附加更多信息上去。比如,附加个与channel一起使用的buffer,或者聚合更多数据的对象。例如:
1 | selectionKey.attach(theObject); |
也可以在注册时附加对象,像这样:
1 | SelectionKey key = channel.register(selector, SelectionKey.OP_READ, theObject); |
通过Selector选择Channel
一旦向Selector注册了一个或多个channel,就可以调用任一select()方法。这些方法返回那些注册时感兴趣事件(connect,accept,read 或者 write)的channel。
也就是说,如果感兴趣的channel已对读数据做好准备,那么在调用select()方法以后,就会返回对读就绪的channel。
select方法有以下几种:
int select()int select(long timeout)int selectNow()
select() 阻塞直到至少一个channel已经对监听事件做好准备。
select(long timeout) 和select()一样,除了最长会阻塞timeout毫秒(参数)。
selectNow() 不会阻塞,无论channel有没有准备好都会直接返回。(没有准备好的直接返回0)
select()方法返回的int值表示有多少通道已经就绪。亦即,自上次调用select()方法后有多少通道变成就绪状态。如果调用select()方法,因为有一个通道变成就绪状态,返回了1,若再次调用select()方法,如果另一个通道就绪了,它会再次返回1。如果对第一个就绪的channel没有做任何操作,现在就有两个就绪的通道,但在每次select()方法调用之间,只有一个通道就绪了。
selectedKeys()
调用select()方法后,一旦其返回值表明一个或多个channel就绪,就可以通过selectedKeys()方法访问『selected key set』(已选择键集)中的就绪channel。
1 | Set<SelectionKey> selectedKeys = selector.selectedKeys(); |
调用Channel.register()向selector注册channel以后返回SelectionKey对象。这个对象就代表了注册到selector的channel。可以通过SelectionKey对象的electedKeySet()方法获得这些对象。
遍历已选择的键集获得就绪的channel:
1 | Set<SelectionKey> selectedKeys = selector.selectedKeys(); |
这个循环遍历已选择键集中的每个键,并检测各个键所对应的通道的就绪事件。
注意在每次遍历后调用keyIterator.remove()方法。Selector不会从已选择键集中自动删除SelectionKey的实例。在处理完channel后必须调用此方法。下次channel会准备好,Selector将其重新添加到已选择的键集中。 (原文:Notice the keyIterator.remove() call at the end of each iteration. The Selector does not remove the SelectionKey instances from the selected key set itself. You have to do this, when you are done processing the channel. The next time the channel becomes “ready” the Selector will add it to the selected key set again.)
调用SelectionKey.channel()方法会返回需要处理的channel。比如ServerSocketChannel或者SocketChannel等。
wakeUp()方法
某个线程调用select()方法以后会被阻塞,即使没有就绪的channel,也可以使其从select()方法返回。只要让其它线程在第一个线程调用select()方法的那个对象上调用Selector.wakeup()方法即可。阻塞在select()方法上的线程会立马返回。
如果有其它线程调用了wakeup()方法,但当前没有线程阻塞在select()方法上,下个调用select()方法的线程会立即“醒来(wake up)”。
close()方法
用完Selector后调用其close()方法会关闭该Selector,且使注册到该Selector上的所有SelectionKey实例无效。通道本身并不会关闭。
完整的Selector示例
下面是一个完整的selector例子,open,register,监听等
1 | Selector selector = Selector.open(); |
Java NIO Channel之间的数据传输
原文:http://tutorials.jenkov.com/java-nio/channel-to-channel-transfers.html
在Java NIO 中channel之间可以直接相互传输。比如一个FileChannel类型的channel,FileChannel类提供transferTo()和transferFrom()两个方法做这个事情。
transferFrom()
FileChannel.transferFrom()方法将一个channel的数据传入FileChannel。
代码🌰:
1 | RandomAccessFile fromFile = new RandomAccessFile("fromFile.txt", "rw"); |
position参数确定目标文件的传输初始位置,count参数确定传输的最大数量。channel中的字节数若是少于count,就读取全部字节。
另外,SocketChannel传输的是其内部此时此处的就绪的数据(SocketChannel后续可能还会有更多的可用数据)。因此,从SocketChannel传输数据时,有可能不能把全部的请求数据(不足count的数据)都传入FileChannel中。
transferTo()
transferTo()方法将FileChannel数据传入其他的channel中。
代码🌰:
1 | RandomAccessFile fromFile = new RandomAccessFile("fromFile.txt", "rw"); |
和上面的例子很相似。区别在于调用方法的FileChannel对象不一样。
关于SocketChannel的问题在transferTo()方法中同样存在。SocketChannel会一直传输数据直到目标buffer被填满。
Java NIO Scatter / Gather
原文:http://tutorials.jenkov.com/java-nio/scatter-gather.html
Java NIO 从一开始就内嵌了scatter/gather的支持。scatter/gather是从channel中读取写入的操作概念。
scatter:从channel中将数据读到多个buffers中的操作。也就是说,channel的分散器将channel中的数据分散到多个buffers。
gather:将多个buffers中的数据写入一个channel中的操作。也就是说,channel的收集器,将多个buffers中的数据收集到channel中。
scatter/gatter经常用于需要将传输的数据分开处理的场合。比如,一个信息包含head和body,你可能会将消息体和消息头分散到不同的buffer中,这样你可以方便的处理消息头和消息体。
Scattering Reads
Scattering Reads,将单个channel中的数据读到多个buffers中,下面是原理图示:

代码🌰:
1 | ByteBuffer header = ByteBuffer.allocate(128); |
注意buffer首先被插入到数组,然后再将数组作为channel.read() 的输入参数。read()方法按照buffer在数组中的顺序将从channel中读取的数据写入到buffer,当一个buffer被写满后,channel紧接着向另一个buffer中写。
Scattering Reads在移动下一个buffer前,必须填满当前的buffer,这也意味着它不适用于动态大小消息。换句话说,如果存在消息头和消息体,消息头必须完成填充(例如填满128byte),Scattering Reads才能正常工作。
Gathering Writes
Gathering Writes:将多个buffers中的数据写入单个channel,下面是原理图示:

代码🌰:1
2
3
4
5
6
7ByteBuffer header = ByteBuffer.allocate(128);
ByteBuffer body = ByteBuffer.allocate(1024);
//write data into buffers
ByteBuffer[] bufferArray = { header, body };
channel.write(bufferArray);
The array of buffers are passed into the write() method, which writes the buffers数组是write()方法的入参,write()方法会按照buffer在数组中的顺序,将数据写入到channel,注意只有position和limit之间的数据才会被写入。因此,如果一个buffer的容量为128byte,但是仅仅包含58byte的数据,那么这58byte的数据将被写入到channel中。因此与Scattering Reads相反,Gathering Writes能较好的处理动态消息。
IntelliJ 使用说明
安装
Windows下载地址:https://www.jetbrains.com/idea/download/#section=windows
版本选择Ultimate
下载的文件直接双击一路next安装即可。安装结束以后运行起来后,通过Server方式破解

http://idea.iteblog.com/key.php
项目引入
破解以后,一路默认启动起来。先创建个Project,Intellij里面的project相当于workplace,可以先建一个空的project的,将项目代码检出到project里面(也可以将原有的项目copy到project文件夹下,如果不想copy,直接import也可以),然后在里面import module
检出代码后的效果:
import后的效果:



配置
intellij的所有配置信息都在 File->Settings里面,请自行摸索。

这里说说常用的几个配置在哪里。
1、项目结构


这里面可以配置module的语言版本,添加jdk,jar引入等
2、maven


3、Server
以tomcat为例


配置好Server的基本信息,完成这一步保存,然后添加具体的Server

添加本地Server,Server标签页更改端口等配置信息

Deployment里面部署war包,点击加号,选择


外观字体样式修改
通过File->Import Setting可以直接导入Intellij的配置信息。我这里有个jar包,直接导入即可
jar地址:https://pan.baidu.com/s/1kU6DxZL
导入重启即可,调整了字体大小,文件注释模板,默认UTF-8,使用了sublime类似的主题。
git 常用命令
基本命令
代码检出:git clone 地址
文件修改添加到暂存区:git add readme.txt
文件提交:git commit -m “备注”
查看工作区当前状态:git status
查看差异:git diff 文件名
查看历史:git log –pretty=oneline
查看历史提交commit id:git log –pretty=oneline –abbrev-commit
恢复当前版本:git reset –hard HEAD
恢复上一个版本:git reset –hard HEAD^
(上上一个版本就是HEAD^^,当然往上100个版本写100个^比较容易数不过来,所以写成HEAD~100)
恢复指定版本:git reset –hard 3628164
查看命令历史:git reflog
查看工作区和版本库区别:git diff HEAD – readme.txt
撤销修改:git checkout – readme.txt
撤销缓存区文件:git reset HEAD readme.txt
删除文件:git rm test.txt
分支命令
查看分支:git branch
创建分支:git branch
切换分支:git checkout
创建+切换分支:git checkout -b
推送远程分支:git push origin
创建远程分支:git checkout -b dev origin/dev
git checkout -b paytest_20151202_online origin/paytest_20151202_online
合并某分支到当前分支:git merge
合并分支禁用Fast forward:git merge –no-ff -m “备注” dev
删除分支:git branch -d
删除远程分支:git push origin –delete
强制删除分支:git branch -D
查看分支历史:git log –graph –pretty=oneline –abbrev-commit
分支合并图:git log –graph
储藏工作区:git stash
查看储藏的工作区:git stash list
恢复并删除储藏工作区:git stash pop
恢复指定工作区:git stash apply stash@{0}
恢复储藏工作区:git stash apply
删除储藏工作区:git stash drop
查询远程库详细信息:git remote -v
推送分支:git push origin dev
抓取最新文件:git pull 分支名
取远程分支:git pull origin 分支名
指定分支与远程分支链接:git branch –set-upstream dev origin/dev
标签命令
创建标签:git tag v1.0
删除本地标签:git tag -d v0.1
删除远程标签:git push origin :refs/tags0.9
删除远程标签:git push origin –delete tag
查看标签:git tag
指定commit id创建标签:git tag v0.9 6224937
指定标签信息:git tag -a
可以用PGP签名标签:git tag -s
查看标签信息:git show 标签名
推送标签到远程:git push origin v1.0
推送所有标签到远程:git push origin –tags
其他
配置别名:git config –global alias.st status
在Git工作区的根目录下创建一个特殊的.gitignore文件,然后把要忽略的文件名填进去,Git就会自动忽略这些文件。
撤銷git add . => git rm -r –cached .
java应用结合Jenkins,docker部署到Kubernetes
Jenkins安装
1、下载Jenkins war包安装,下载地址 jenkins.io。这里使用的是Jenkins2.24版本
2、启动Jenkins
1 | JENKINS_HOME=~/.jenkins java -jar ~/Downloads/jenkins-2.24.war --httpPort=9090 |
启动后,日志会提示1
*************************************************************
*************************************************************
*************************************************************
Jenkins initial setup is required. An admin user has been created and a password generated.
Please use the following password to proceed to installation:
3521fbc3d40448efa8942f8e464b2dd9
This may also be found at: /Users/arungupta/.jenkins/secrets/initialAdminPassword
*************************************************************
*************************************************************
*************************************************************
访问localhost:9090,输入上面提示的密码,然后根据提示,安装推荐的插件,并创建用户
使用kubeadm在CentOS7上安装Kubernetes集群
Kubernetes1.4版本提供kubeadm命令进行简化k8s集群的安装,只要使用2个简单命令就可以完成安装。 安装kubernetes以后,使用kubeadm init启动master,使用kubeadm joins把node添加到集群里。下面是根据官方博客Installing Kubernetes on Linux with kubeadm练习的记录。
使用vagrant创建两个centos7
在k8s-centos7-cluster文件夹下创建Vagrantfile文件。Vagrantfile配置如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30# -*- mode: ruby -*-
# vi: set ft=ruby :
boxes = [
{ :name => :master,:ip => '192.168.1.20',:forward => 80,:cpus => 1,:mem => 1024},
{ :name => :node1,:ip => '192.168.1.21',:forward => 80,:cpus => 1,:mem => 1024},
]
VAGRANTFILE_API_VERSION = "2"
Vagrant.configure(VAGRANTFILE_API_VERSION) do |config|
boxes.each do |opts|
config.vm.define opts[:name] do |config|
config.vm.box = "centos7"
config.vm.boot_timeout = 360
config.ssh.username = "vagrant"
config.ssh.password = "vagrant"
config.vm.synced_folder ".", "/vagrant", disabled:true
config.vm.network "public_network", ip: opts[:ip]
#config.vm.network "forwarded_port", guest: 80, host: 8080
config.vm.hostname = "%s.vagrant" % opts[:name].to_s
config.vm.provider "virtualbox" do |vb|
vb.customize ["modifyvm", :id, "--cpus", opts[:cpus] ] if opts[:cpus]
vb.customize ["modifyvm", :id, "--memory", opts[:mem] ] if opts[:mem]
end
#config.vm.provision "shell", inline: $update_script
#config.vm.provision "shell", path: opts[:provision] if opts[:provision]
end
end
end
在Vagrantfile文件目录下,创建两个CentOS7系统,一个作为master,一个作为node1
2
3
4➜ k8s-centos7-cluster vagrant up
Bringing machine 'master' up with 'virtualbox' provider...
Bringing machine 'node1' up with 'virtualbox' provider...
...
Ok,下面我们开始在CentOS7中安装k8s集群
安装kubelet和kuebadm
在所有的机子上都必须安装docker,kubelet,kubectl,kubeadm,无论是master还是node。并且使用root权限进行安装。
1 | ➜ k8s-centos7-cluster vagrant ssh master #输入密码登录master |
登录master,切换到root用户,然后执行下面的命令:
1 | # cat <<EOF > /etc/yum.repos.d/k8s.repo [kubelet] name=kubelet baseurl=http://files.rm-rf.ca/rpms/kubelet/ enabled=1 gpgcheck=0 EOF # yum install docker kubelet kubeadm kubectl kubernetes-cni # systemctl enable docker && systemctl start docker # systemctl enable kubelet && systemctl start kubelet |
等待下载后安装。
安装完成后,可以使用systemctl status 查看安装好的组件服务状态。
1 | [root@master ~]# systemctl status docker |
初始化master
在master上运行控制组件,包含etcd(集群的数据库),API server(kubectl 客户端沟通用)。这些组件都在pod中通过kubelet启动运行。
初始化master,选择上面实现安装过kubelet和kubeadm的主机,然后运行下面的命令:
1 | [root@master ~]# kubeadm init --use-kubernetes-version v1.4.0-beta.11 |
运行后,会下载安装集群用的数据库和控制组件,需要等待一些时间,输出内容如下:
1 | <master/tokens> generated token: "88958f.2068ff49c1675f8c" |
未完待续。。。
基于Docker的java微服务(三) Kubernetes服务发现之环境变量
- 创建两个服务
- 将服务打包成镜像
- k8s的service
- k8s的deployment
- 简单测试
基于Docker的java微服务(二) CentOS7部署Kubernetes集群
本文主要参考美团云的在CentOS7上部署Kubernetes集群
概述
Kubernetes(k8s)是Google开源的大规模容器集群管理系统, 本文将基于CentOS7自带的Kubernetes组件、分布式键值存储系统etcd以及Flannel实现的overlay网络来搭建一个简单的k8s集群。
vagrant安装多台CentOS7
使用vagrant创建多个CentOS7虚拟机用于集群部署。vagrant的安装非常简单,网上一大堆教程,可以参考这里。我使用的是1.8.5版本。同时还需要下载CentOS的box文件,
由于box文件都在国外的网站上下载速度缓慢,可以从我的云盘上下载CentOS-7-x86_64-Minimal-1511.box。
有了box文件后,执行以下命令添加box
1 | vagrant add box CentOS-7-x86_64-Minimal-1511.box |
查看vagrant已添加的box
1 | vagrant box list |
创建单台CentOS很简单,需要下面的步骤
1 | mkidr centos7 |
vagrant init会初始化一个Vagrantfile的文件,CentOS的配置都是这个文件设定的。这里给出创建多台centos的Vagrantfile配置。
1 | # -*- mode: ruby -*- |
在这个文件的目录下执行vagrant up就可以创建3台虚拟机。我们把其中master作为k8s的Master节点,worker1,worker2作为k8s的Node节点来创建k8s集群。
环境准备
| master | worker1 | worker2 |
|---|---|---|
| 192.168.253.7 | 192.168.253.8 | 192.168.253.9 |
| kubernetes | ntpd | ntpd |
| etcd | flannel | flannel |
| ntpd | kubernetes | kubernetes |
Master节点禁用CentOS7自带防火墙,安装kubernetes、etcd、ntpd等软件。
1 | sudo systemctl stop firewalld && sudo systemctl disable firewalld |
Node节点同样禁用CentOS7自带防火墙,安装kubernetes、flannel、ntpd等软件。
1 | sudo systemctl stop firewalld && sudo systemctl disable firewalld |
Master配置
修改etcd配置/etc/etcd/etcd.conf
1 | ETCD_LISTEN_CLIENT_URLS="http://0.0.0.0:2379" |
修改kubernetes全局配置/etc/kubernetes/config
1 | KUBE_LOG_LEVEL="--v=2" |
修改kubernetes apiserver的配置/etc/kubernetes/apiserver
1 | KUBE_API_ADDRESS="--address=0.0.0.0" |
启动master的ntpd、etcd、kube-apiserver、kube-scheduler、kube-controller-manager服务,设置为开机启动,并查看启动后的状态。如果每一个服务都启动成功,那么sudo systemctl status $SRV显示的信息则包含Active: active (running)
1 | #!/bin/bash |
修改etcd配置,在设定Node中flannel所使用的子网范围为172.17.1.0~172.17.254.0(每一个Node节点都有一个独立的flannel子网)
1 | etcdctl mk /coreos.com/network/config '{"Network":"172.17.0.0/16", "SubnetMin": "172.17.1.0", "SubnetMax": "172.17.254.0"}' |
Node配置
修改Node节点上flannel的配置/etc/sysconfig/flanneld,设定etcd的相关信息,其中192.168.253.7为Master的IP地址。
1 | FLANNEL_ETCD="http://192.168.253.7:2379" |
修改Node节点kubernetes的全局配置文件/etc/kubernetes/config
1 | KUBE_LOG_LEVEL="--v=2" |
修改Node节点上kubernetes kubelet的配置/etc/kubernetes/kubelet
1 | KUBELET_ADDRESS="--address=0.0.0.0" |
启动Node节点上的相关服务1
2
3
4
5
6
7#!/bin/bash
for SRV in ntpd flanneld docker kube-proxy kubelet;
do
sudo systemctl start $SRV
sudo systemctl enable $SRV
sudo systemctl status $SRV
done
类似Master节点,如果每一个服务都启动成功,那么sudo systemctl status $SRV显示的信息则包含Active: active (running)。
配置步骤都是参考美团云在CentOS7上部署Kubernetes集群。
不巧的是,我在这一步上花了1周的时间。。。。Node节点上的flanneld和docker服务死活起不起来。
通过systemctl status flanneld,发现一直报错Failed to retrieve network config。
解决方法:
修改Node节点上的flanneld配置 /etc/sysconfig/flanneld
1 | FLANNEL_ETCD_KEY="/coreos.com/network" |
然后重新启动flanneld和docker服务即可。
测试
在Master上查看节点信息
1 | [vagrant@master ~]$ kubectl get nodes |
在Master节点查看flannel子网分配情况
1 | [vagrant@master ~]$ etcdctl ls /coreos.com/network/subnets |
Guestbook部署到k8s中
部署的过程中遇到2个问题
通过
kubectl create -f xxx.yaml创建pod显示成功,但是通过kubectl get pod命令确查询不到任何pod信息。解决方案可以参考: kubenetes无法创建pod/创建RC时无法自动创建pod的问题解决了上面的问题后,可以get到pod信息,但是node节点通过查询docker images并未发现任何镜像,原因是因为国内的网络问题,无法下载到镜像所致。可以手动pull
镜像:registry.access.redhat.com/rhel7/pod-infrastructure以及你所需的其他镜像。
总结
这里的集群部署参考的是美团云分享的。都只是练手用的。
k8s部署还可以更简单,一键部署。使用vagrant+coreOs,安装完虚拟机后,Master节点c1会自动下在k8s所需的环境,奈何大陆的程序员比较苦逼,有墙的存在。在翻墙的情况下可以尝试一键部署k8s集群。详情请移步要翻才能看的到。
基于Docker的java微服务(一) 部署Chris Richardson的转账案例
概述
本文主要参考使用DCHQ自动部署和管理基于Docker的云/虚拟化环境Java微服务
最近在学习微服务,前两周了解基于Spring Cloud的微服务框架,这两天开始看看关于Docker的微服务。
Spring Cloud整合了Netflix开源的Eureka,Hystrix,Ribbon,Feign,ZUUL等,
是一个基于Spring Boot实现的云应用开发工具,它为基于JVM的云应用开发中的配置管理、服务发现、断路器、智能路由、微代理、控制总线、全局锁、决策竞选、
分布式会话和集群状态管理等操作提供了一种简单的开发方式(参考DIDI)。
那么Docker的微服务是什么样的呢。有空的同学可以看看Spring Cloud和Docker的比较
Netflix OSS、Spring Cloud还是Kubernetes?。
简单的说,就是基于Docker的调度器Kubernetes可以帮忙把大家从服务发现、负载均衡、容错等功能中解放出来,更专注于业务逻辑开发。
Kubernetes是个什么鬼?要了解它,我们得先了解下,我们开发好的项目是怎么在Docker上部署应用的,多个Docker容器又是如何管理的。
这篇文章是Chris Richardson针对事件溯源、CQRS和Docker所创建的转账案例。
案例主要功能如下:
- 基于一个初始的余额,创建新账户
- 查询某个账户,得到其余额
- 从一个账户到另一个账户进行转账
我们就用这个例子,来了解下整个开发部署流程(仅仅是了解)。案例的具体业务逻辑介绍请移步event-sourcing-examples
获取Event Store凭证
架构使用事件驱动的方式来确保数据的一致性,这里面使用的是Event Store。
在使用之前,需要获取Event Store凭证。
进入Event Store官网,注册个账号,过几个小时一般就会收到来自chris的邮件。
邮件中有EVENTUATE_API_KEY_ID和EVENTUATE_API_KEY_SECRET,这个在后面的yml模板里会用到。
gradle构建
从event-sourcing-examplesclone项目到本地。
直接下载下来的例子,部署测试的时候,会报几个错误,需要对代码做部分修改
- 修改 xx-xx-side-service模块中build.gradle文件,添加如下内容
1
2
3
4
5jar {
manifest {
attributes 'Main-Class': 'net.chrisrichardson.eventstore.javaexamples.banking.web.main.XxxxSideServiceMain'
}
}
添加这个解决部署时遇到的找不到manifest错误
- xx-xx-side-service主方法添加注解@SpringBootApplication
主方法没有@SpringBootApplication这个注解,是无法启动spring boot滴。
修改后,使用gradle的assemble命令构建,构建成功后,模块的/build/libs会生成jar包。
docker-compose
gradle构建完毕后,我们要把service模块的jar包放到一个docker镜像中,然后启动这个docker。
这里使用了docker-compose来生成启动镜像。
docker-compose的安装及介绍,请移步:Docker Compose 项目
docker-compose.yml
docker-compose管理调度docker容器默认是根据docker-compose.yml模板进行的。这个模板里定义了生成镜像部署镜像的一些步骤。
本案例的yml如下:
1 | accountscommandside: image: openjdk:8u92-jdk-alpine working_dir: /app volumes: - ./accounts-command-side-service/build/libs:/app command: java -jar /app/accounts-command-side-service.jar ports: - "8080:8080" environment: EVENTUATE_API_KEY_ID: 5NJSVTRJ6UTYVL8U4RN8TKDRM EVENTUATE_API_KEY_SECRET: fiAKWYEEj7EVxNi6yKXF8WDcVLbYA8Cu5RnFFKjwVOw transactionscommandside: image: openjdk:8u92-jdk-alpine working_dir: /app volumes: - ./transactions-command-side-service/build/libs:/app command: java -jar /app/transactions-command-side-service.jar ports: - "8082:8080" environment: EVENTUATE_API_KEY_ID: 5NJSVTRJ6UTYVL8U4RN8TKDRM EVENTUATE_API_KEY_SECRET: fiAKWYEEj7EVxNi6yKXF8WDcVLbYA8Cu5RnFFKjwVOw accountsqueryside: image: openjdk:8u92-jdk-alpine working_dir: /app volumes: - ./accounts-query-side-service/build/libs:/app command: java -jar /app/accounts-query-side-service.jar ports: - "8081:8080" links: - mongodb environment: EVENTUATE_API_KEY_ID: 5NJSVTRJ6UTYVL8U4RN8TKDRM EVENTUATE_API_KEY_SECRET: fiAKWYEEj7EVxNi6yKXF8WDcVLbYA8Cu5RnFFKjwVOw SPRING_DATA_MONGODB_URI: mongodb://mongodb/mydb mongodb: image: mongo:3.2.9 hostname: mongodb command: mongod --smallfiles ports: - "27017:27017" |
这里面定义了4个容器内容,分别是accountscommandside,transactionscommandside,accountsqueryside,mongodb
- image:指定为镜像名称或镜像 ID。如果镜像在本地不存在,Compose 将会尝试拉取这个镜像
- volumes:卷挂载路径设置,这里是将容器的/app路径挂载到宿主机/build/libs 路径上
- command:覆盖容器启动后默认执行的命令,这里是默认直接启动spring boot项目
- ports:暴露端口信息,格式如下
- 宿主:容器 (HOST:CONTAINER)
- 容器(宿主会随机选择端口)
- links:链接到其它服务中的容器。使用服务名称(同时作为别名)或服务名称:服务别名 (SERVICE:ALIAS)格式都可以。
- db
- db:database
- redis
- environment:设置环境变量
替换成你自己的EVENTUATE_API_KEY_ID和EVENTUATE_API_KEY_SECRET,否则部署后运行测试,会报401未授权错误。
docker-compse up
设置好yml模板以后,使用docker-compse up来启动这4个容器
1 | ➜ java-spring git:(master) ✗ docker-compose up |
再开个shell,看下启动的四个容器的状态
1 | ➜ java-spring git:(master) ✗ docker-compose ps |
四个状态都是up,好了,访问服务测试下。
测试
先创建2个账户,每个都初始500美元1
2
3
4➜ java-spring git:(master) ✗ curl -X POST -H "Content-Type: application/json" -H "Cache-Control: no-cache" -d '{"initialBalance": 500}' "http://localhost:8080/accounts"
{"accountId":"00000156bfc1c044-0242ac1100460000"}%
➜ java-spring git:(master) ✗ curl -X POST -H "Content-Type: application/json" -H "Cache-Control: no-cache" -d '{"initialBalance": 500}' "http://localhost:8080/accounts"
{"accountId":"00000156bfc1da88-0242ac1100960000"}%
根据账户ID查询1
2
3
4➜ java-spring git:(master) ✗ curl -X GET "http://localhost:8081/accounts/00000156bfc1c044-0242ac1100460000"
{"accountId":"00000156bfc1c044-0242ac1100460000","balance":50000}%
➜ java-spring git:(master) ✗ curl -X GET "http://localhost:8081/accounts/00000156bfc1da88-0242ac1100960000"
{"accountId":"00000156bfc1da88-0242ac1100960000","balance":50000}%
可以看到每个账户里都有50000美分。试试转账,然后再查询1
2
3
4
5
6
7
8➜ java-spring git:(master) ✗ curl -X POST -H "Content-Type: application/json" -d '{"fromAccountId" : "00000156bfc1c044-0242ac1100460000", "toAccountId" : "00000156bfc1da88-0242ac1100960000", "amount" : 500}' "http://localhost:8082/transfers"
{"moneyTransferId":"00000156bfc75387-0242ac1100ac0000"}%
➜ java-spring git:(master) ✗ curl -X GET "http://localhost:8081/accounts/00000156bfc1da88-0242ac1100960000"
{"accountId":"00000156bfc1da88-0242ac1100960000","balance":50000}%
➜ java-spring git:(master) ✗ curl -X GET "http://localhost:8081/accounts/00000156bfc1c044-0242ac1100460000"
{"accountId":"00000156bfc1c044-0242ac1100460000","balance":0}%
➜ java-spring git:(master) ✗ curl -X GET "http://localhost:8081/accounts/00000156bfc1da88-0242ac1100960000"
{"accountId":"00000156bfc1da88-0242ac1100960000","balance":100000}%
可以看到中间有个状态是不对的,这个基于事件驱动的,还没有自己看,应该是有延迟,后来再查询就是准确的了。事件驱动的后面会专门看看再整理篇文章。
结语
本篇主要描述了如何使用docker-compose构建基于docker的java微服务框架。后续会对里面的知识点做些详细的学习。
Spring Cloud构建微服务架构(四)集群
前面三篇都分享自程序猿DD的博客,暂时(2016年08月05日)还没有更新关于Eureka集群的博客。
这里参考了木木彬的Spring Cloud实战(二)-Spring Cloud Eureka博客内容。
对集群配置简单记录下,方便以后查阅。同时也期待程序猿DD更新更多更精彩的博客。
本文代码基于程序猿DD / SpringBoot-Learning / Chapter9-1-3进行集群配置。
Spring Cloud 官方文档上对集群配置介绍的非常简单,对Eureka Server进行Peer Awareness配置,这样多个服务端就可以关联到一起。好了,下面看看具体的配置。
hosts修改
在hosts(路径:/etc/hosts)文件中添加
1 | 127.0.0.1 eureka-primary 127.0.0.1 eureka-secondary 127.0.0.1 eureka-tertiary |
服务端配置
先注释掉application.properties中的配置,添加application.yml,在yml添加多个profiles,和instanceId,此时Eureka Server 同时也是个Eureka Client,需要设置eureka.client.serviceUrl.defaultZone,值是另外两个(这就是官网所说的Peer Awareness):
1 | --- spring: application: name: eureka-server-clustered profiles: primary server: port: 1111 eureka: instance: hostname: eureka-primary client: registerWithEureka: true fetchRegistry: true serviceUrl: defaultZone: http://eureka-secondary:1112/eureka/,http://eureka-tertiary:1113/eureka/ --- spring: application: name: eureka-server-clustered profiles: secondary server: port: 1112 eureka: instance: hostname: eureka-secondary client: registerWithEureka: true fetchRegistry: true serviceUrl: defaultZone: http://eureka-secondary:1111/eureka/,http://eureka-tertiary:1113/eureka/ --- spring: application: name: eureka-server-clustered profiles: tertiary server: port: 1113 eureka: instance: hostname: eureka-tertiary client: registerWithEureka: true fetchRegistry: true serviceUrl: defaultZone: http://eureka-secondary:1111/eureka/,http://eureka-tertiary:1112/eureka/ |
服务端启动
配置完成,要分别启动3个Server,分别执行下面的命令即可:
1 | ➜ eureka-server git:(master) ✗ mvn clean && mvn install |
1 | ➜ target git:(master) ✗ java -Dspring.profiles.active=secondary -jar eureka-server-0.0.1-SNAPSHOT.jar |
1 | ➜ target git:(master) ✗ java -Dspring.profiles.active=tertiary -jar eureka-server-0.0.1-SNAPSHOT.jar |
我们访问其中一个服务地址http://localhost:1111/ 可以看到如下内容,说明服务启动成功:

客户端配置
服务端已准备就绪,客户端如何注册到多个服务地址呢?其实在服务端配置defaultZone时,指定多个地址,就告诉我们客户端也这么指定就可以啦。
修改compute-service的application.properties中的defaultZone值
1 | #指定微服务的名称后续在调用的时候只需要使用该名称就可以进行服务的访问 spring.application.name=compute-service #应用端口 server.port=2222 #指定服务注册中心的位置 #eureka.client.serviceUrl.defaultZone=http://localhost:1111/eureka/ eureka.client.serviceUrl.defaultZone=http://eureka-primary:1111/eureka/,http://eureka-secondary:1112/eureka/,http://eureka-tertiary:1113/eureka/ |
启动客户端
客户端默认端口是2222,我们启动2个客户端,另一个端口用2223好了。
1 | ➜ compute-service git:(master) ✗ mvn clean && mvn insatll |
1 | ➜ target git:(master) ✗ java -DServer.port=2223 -jar compute-service-0.0.1-SNAPSHOT.jar |

2个客户端启动成功了。
测试
启动消费者eureka-ribbon成功后,简单测试下
1 | ➜ ~ curl localhost:3333/add |
一个客户端也打出了日志
1 | 2016-08-05 11:18:23.554 INFO 5127 --- [nio-2223-exec-1] com.ow.wises.web.ComputeController : /add, host:192.168.1.145, service_id:compute-service, result:30 |
好了,就先这样了。
Java NIO Buffer
原文:http://tutorials.jenkov.com/java-nio/buffers.html
Java NIO Buffers是和NIO的Channels交互使用的。你知道的,数据是从Channel中读到Buffer里,数据从Buffer里写入到Channel中。
Buffer本质上是可以读写数据的内存块。这个内存块被NIO的Buffer对象包裹,然后提供很多方法以便能够简单的操作这个内存块。
Buffer基础用法
使用Buffer读写数据基本上就4步:
- 数据写入Buffer
- 调用
buffer.flip() - 从Buffer中读出数据
- 调用
buffer.clear()或者buffer.compact()方法
当你将数据写入buffer,buffer会一直留意你已经写了多少数据。一旦你需要读数据,你必须调用flip()方法将buffer从写模式切换到读模式中。进入读模式后,buffer允许你读取其中被写入的数据。
一旦你读完了所有的数据,你需要清空buffer,以备buffer可以继续被写入。这么做有两种方式:调用clear()方法或者调用compact()方法。clear()方法会清空buffer中的所有数据。compact()方法只会清楚掉你已经读过的数据。那些没读的数据会移到buffer的起始处,然后数据会接着这些未读数据后面继续写入。
栗子
下面是Buffer用法的🌰,用到的write,flip,read,clear等操作会作注释说明。
1 | public class JavaNIOBuffer { |
Buffer Capacity, Position and Limit
buffer本质上就是一个你写入数据,然后读取数据的内存块。这个内存块被NIO Buffer对象包裹后,提供了一系列简单操作内存块的方法。
Buffer有3个你需要了解的属性:
- capacity
- position
- imit
position和limit的含义取决于Buffer处在读模式还是写模式。capacity含义一直都是一样的,和Buffer模式无关。
这是一个关于capacity,position和limit的说明,后面会对其进行说明。
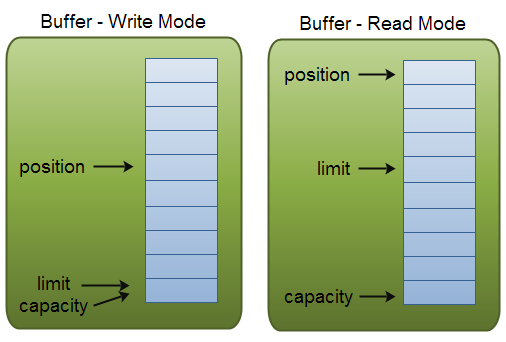
Capacity
Buffer作为一个内存块是有固定的大小值,称之为『capacity』。你只能向Buffer中写入byte,long,char等类型数据。一旦Buffer满了,在向其写入数据之前你需要清空它(读取数据或者清空数据)
Position
向Buffer中写数据是从一个确定的position开始,初始的position是0。当byte,long等数据写入Buffer,position会向前移动到下一个可供插入数据的单元。position最大值为capacity-1。
从Buffer中读数据也是从一个给定的位置开始。当你将Buffer从写模式切换到读模式后,position的值重置为0。从Buffer中读数据就是从position读,读取后,position会向前移动到下一个可供读取的单元。
Limit
写模式中,limit就是写入buffer的数据量。Limit等于buffer的capacity。
当切换到读模式后,limit就是buffer中可以读取的数据量。就是说,切换到读模式时,limit就是设置为写模式中position的值。也就是说,buffer中写入的数据都可以读取到。
Buffer的类型
伴随Java NIO的Buffer类型有:
- ByteBuffer
- MappedByteBuffer
- CharBuffer
- DoubleBuffer
- FloatBuffer
- IntBuffer
- LongBuffer
- ShortBuffer
可以看到,这些Buffer类型表示了不同的数据类型。换句话说,就是可以通过char,short,int,long,float 或 double类型来操作缓冲区中的字节。
MappedByteBuffer有点特殊,在它的专门章节中再描述。
Buffer的分配
在获取到Buffer对象后首先要去分配。每个Buffer类都有个allocate()方法。下面的例子是ByteBuffer分配capacity为48字节的例子:
1 | ByteBuffer buf = ByteBuffer.allocate(48); |
Here is an example allocating a CharBuffer with space for 1024 characters:
下面是CharBuffer分配1024个字符的例子:1
CharBuffer buf = CharBuffer.allocate(1024);
向Buffer中写入数据
向Buffer中写入数据有两种方式:
- 从Channel中获取数据写入Buffer
- 通过buffer的
put()方法写入数据
从Channel中获取数据写入buffer的例子:1
int bytesRead = inChannel.read(buf);//read into buffer.
使用put()方法写入数据的例子:
1 | buf.put(127); |
有不同的版本的put()方法,允许你使用不同的方式写入数据。比如,在特定的位置写入,写入字节或数组。查看JavaDoc获取buffer具体的实现。
flip()
flip()方法用来切换Buffer的读和写模式。调用flip(),设置position为0,设置limit为原来的position值。就是说,position现在用来标记读的位置,Limit用来标记可以读多少。
从Buffer中读数据
从Buffer中读取数据有两种方式:
- 将buffer中的数据读入到channel中
- 调用buffer自带的
get()方法直接读
举个🌰:将Buffer中的数据读到channel中
1 | //read from buffer into channel. |
举个🌰:使用get()方法读取Buffer1
byte aByte = buf.get();
有不同的版本的get()方法,允许你使用不同的方式写入数据。比如,在特定的位置写入,写入字节或数组。查看JavaDoc获取buffer具体的实现。
rewind()
Buffer.rewind()重置position为0,这样就可以重新读buffer的数据。limit不受影响,始终可以标记buffer中可读的数据量。
clear() and compact()
从Buffer中读完数据以后要做好Buffer写的准备。可以调用clear()方法或者compact()方法。
调用clear()方法会重置position的值为0,Limit的值为capacity。意思是,Buffer已经清空。Buffer中的数据并没有清楚掉。只是告诉你从Buffer的哪个位置可以写入数据。
如果存在没有读取的数据,调用clear()方法后,该数据会被标记为’遗忘的’,因为这些数据再也没有什么标记其实被读过的还是没被读过的。
如果你必须先向Buffer中写入数据,然后还想读那些没有被读过的数据。需要调用compact()方法代替clear()方法。
compact()方法把所有没有读过的数据复制到Buffer的起始处。然后设置position的值为味道数据后面的值。Limit仍然设置为capacity。这样,Buffer就做好写的准备,而不必覆盖掉未读的数据。
mark() and reset()
使用Buffer.mark()方法可以标记一个指定的position。这样再之后调用Buffer.reset()方法重置position到标记的地方。
举个🌰:1
2
3buffer.mark();
//call buffer.get() a couple of times, e.g. during parsing.
buffer.reset(); //set position back to mark.
equals() and compareTo()
比较两个buffers仍然可以使用equals()和compareTo()方法。
equals()
两个buffers相等,那么:
- 有相同的类型(byte、char、int等)。
- Buffer中剩余的byte、char等的个数相等。
- Buffer中所有剩余的byte、char等都相同。
就是说:equals只是比较Buffer的一部分,不是每一个在它里面的元素都比较。实际上,它只比较Buffer中的剩余元素。
compareTo()
compareTo()方法比较两个Buffer的剩余元素(byte、char等), 如果满足下列条件,则认为一个Buffer“小于”另一个Buffer:
- 第一个不相等的元素小于另一个Buffer中对应的元素 。
- 所有元素都相等,但第一个Buffer比另一个先耗尽(第一个Buffer的元素个数比另一个少)。
Java NIO Channel
Java NIO 的Channels有些像流,但是也有一些区别:
- 可以向一个Channel即读又写。流是典型的单向的(写或者读)
- Channels的读写是异步的
- Channels总是读数据到Buffer中,或者将Buffer中的数据写入Channel
上面提到的,从channel中读取数据至buffer中,将buffer中的数据写入channel中:
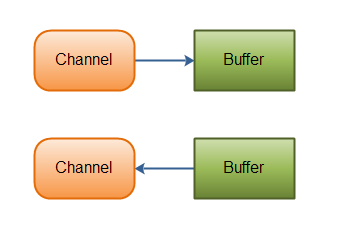
Java NIO: Channels read data into Buffers, and Buffers write data into Channels
Channel Implementations
在Java NIO中有一些比较重要的channel实现类:
- FileChannel
- DatagramChannel
- SocketChannel
- ServerSocketChannel
FileChannel从文件中读取数据。DatagramChannel通过UDP读写网络中的数据。SocketChannel通过TCP读写网络中的数据。ServerSocketChannel可以监听新进来的TCP连接,像Web服务器那样,对每一个新进来的连接都会创建一个SocketChannel。
Basic Channel Example
下面是一个使用FileChannel读数据到Buffer中的例子:
1 | public class ChannelExample { |
注意 buf.flip() 的调用,首先读取数据到Buffer,然后反转Buffer,接着再从Buffer中读取数据。下一节会深入讲解Buffer的更多细节。
Java NIO 概述
Java NIO 包含下面三个核心组件:
- Channels
- Buffers
- Selectors
Java NIO 还有很多其他的类和组件,Channel,Buffer,Selector是核心的API。其他的组件,诸如Pipe、FileLock仅仅只是这3个核心组组件的实际应用。
Channels and Buffers
典型的,NIO中的所有IO都是起始于Channel。Channel有点像流。可以将Channel中数据读到Buffer里,也可以将Buffer里的数据写入Channel中。说明如下:
Java NIO: Channels read data into Buffers, and Buffers write data into Channels
Java NIO中主要的Channel实现类有:
- FileChannel
- DatagramChannel
- SocketChannel
- ServerSocketChannel
可以看出,这些channels覆盖了UDP+TCP的网络IO,以及文件IO。
Java NIO中主要的Buffer实现类有:
- ByteBuffer
- CharBuffer
- DoubleBuffer
- FloatBuffer
- IntBuffer
- LongBuffer
- ShortBuffer
这些实现类也包含了通过IO发送数据所需要的基本的数据类型:byte、short、int、long、float、double、Char型。
Java NIO也有 MappedByteBuffer类型,用于表示内存映射文件。
Selectors
一个Selectors允许一个单线程同时处理多个Channel。如果应用中有很多打开的连接(Channels)这么做是很方便的,但是每个连接的流量都很低。比如,聊天服务器。
下面是一个Selector处理3个Channel的说明:
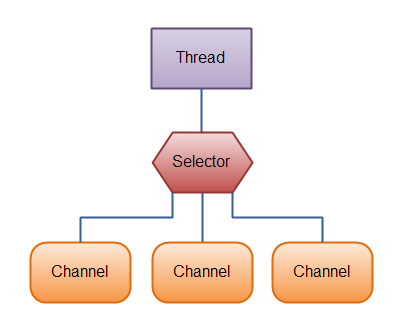
Java NIO: A Thread uses a Selector to handle 3 Channel’s
先将Channels注册到Selector中,然后调用他的select()方法。这个方法会阻塞直到有注册的channel相应的事件触发。一旦这个方法返回,线程就可以处理这个事件。比如正在打开的连接,获取到数据的事件等等。
Java NIO 教程
原文地址Java Reflection
Java NIO(New IO) 是java(从java1.4开始) IO API的一个选择,可以代替Java标准IO和Java网络编程API。对于标准的IO来说,Java NIO提供了不同的处理IO的方式。
Channels and Buffers
在标准的IO API中,使用字节流和字符流。在NIO中需要用到channels和buffers。数据总是从channel获取读到buffer中,从buffer中获取写入channel。
Non-blocking IO
Java NIO 可以非阻塞式的处理IO。比如,一个线程将channel的数据读到buffer。在读的过程中,线程可以做其他事情。一旦数据读取完毕放到buffer中,线程在继续处理。写数据也是一样的操作。
Selectors
Java NIO 有个 『selectors』的概念,一个selector就是一个对象,通过事件(比如:连接打开,数据到达等等)监控多个channels。这样,一个单独的线程就可以监控多个channel的数据。
这些都是如何工作的,本系列的下一章 the Java NIO overview会详细描述。
Java反射之数组
在Java反射里面处理数组有时是比较棘手的.特别是你需要获得数组对象的实际类型.例如 int[]等待.这篇文字就来讨论通过反射如何创建数组如何获取数组中的对象.
java.lang.reflect.Array
通过Java反射使用数组用到的是类java.lang.reflect.Array,不要和Java集合中的java.util.Arrays混淆.
Creating Arrays
通过Java反射创建数组使用类java.lang.reflect.Array,下面给出了创建数组的例子:
1 | int[] intArray = (int[]) Array.newInstance(int.class,3) |
这是创建int类型数组的例子. Array.newInstance()方法的第一个参数int.class给出了数组元素类型,第二个参数3是数组需要分配的空间
Accessing Arrays
通过反射访问数组元素可以使用Array.get()和Array.set()方法:
1 | int[] intArray = (int[]) Array.newInstance(int.class,3); |
打印出来的结果为:
1 | intArray[0] = 123 |
获取数组的Class对象
在我编写Butterfly DI Container的脚本语言时,当我想通过反射获取数组的Class对象时遇到了一点麻烦。如果不通过反射的话你可以这样来获取数组的Class对象:
1 | Class stringArrayClass = String[].class; |
如果使用Class.forName()方法来获取Class对象则不是那么简单。比如你可以像这样来获得一个原生数据类型(primitive)int数组的Class对象:
1 | Class intArray = Class.forName("[I"); |
在JVM中字母I代表int类型,左边的‘[’代表我想要的是一个int类型的数组,这个规则同样适用于其他的原生数据类型。对于普通对象类型的数组有一点细微的不同:
1 | Class stringArrayClass = Class.forName("[Ljava.lang.String;"); |
注意‘[L’的右边是类名,类名的右边是一个‘;’符号。这个的含义是一个指定类型的数组。需要注意的是,你不能通过Class.forName()方法获取一个原生数据类型的Class对象。下面这两个例子都会报ClassNotFoundException:
1 | Class intClass1 = Class.forName("I"); |
我通常会用下面这个方法来获取普通对象以及原生对象的Class对象:
1 | public Class getClass(String className){ |
一旦你获取了类型的Class对象,你就有办法轻松的获取到它的数组的Class对象,你可以通过指定的类型创建一个空的数组,然后通过这个空的数组来获取数组的Class对象。这样做有点讨巧,不过很有效。如下例:
1 | Class theClass = getClass(theClassName); |
这是一个特别的方式来获取指定类型的指定数组的Class对象。无需使用类名或其他方式来获取这个Class对象。
为了确保Class对象是不是代表一个数组,你可以使用Class.isArray()方法来进行校验:
1 | Class stringArrayClass = Array.newInstance(String.class, 0).getClass(); |
获取数组的成员类型
一旦你获取了一个数组的Class对象,你就可以通过Class.getComponentType()方法获取这个数组的成员类型。成员类型就是数组存储的数据类型。例如,数组int[]的成员类型就是一个Class对象int.class。String[]的成员类型就是java.lang.String类的Class对象。
下面是一个访问数组成员类型的例子:
1 | String[] strings = new String[3]; |
下面这个例子会打印java.lang.String代表这个数组的成员类型是字符串。
Java反射之泛型
Generic Method Return Types
如果你已经获取一个java.lang.reflect.Method的对象,就可以获取到该对象上的泛型返回类型信息。如果方法是在一个被参数化类型之中(如T fun())那么你无法获取他的具体类型,但是如果方法返回一个泛型类(如List fun())那么你就可以获得这个泛型类的具体参数化类型。下面这个例子定义了一个类这个类中的方法返回类型是一个泛型类型:
1 | public class MyClass { |
这个例子是可以获取到getStringList()方法的泛型返回类型。可以检测到getStringList()方法返回的List并不仅仅是一个List。
1 | try { |
Type[]数组typeArguments只有一个结果 – 一个代表java.lang.String的Class类的实例。Class类实现了Type接口。
Generic Method Parameter Types
使用Java反射还可以获取参数上的泛型,例子如下:
1 | public class MyClass { |
像下面这样获取参数上的泛型:
1 | Method method2 = MyClass.class.getMethod("setStringList", List.class); |
这段代码打印出”parameterArgType = java.lang.String”。parameterArgTypes这个数组包含的是代表java.lang.String的Class类的实例。Class类实现了Type接口。
Generic Field Types
访问public的泛型变量,无论这个变量是一个类的静态成员变量或是实例成员变量。
1 | public class MyClass { |
1 | Field field = MyClass.class.getField("stringList"); |
这段代码打印出”fieldArgClass = java.lang.String”。fieldArgTypes这个数组包含的是代表java.lang.String的Class类的实例。Class类实现了Type接口。
Java反射之注解
原文地址Java Reflection Annotations
在运行时状态下,你可以通过反射获取java对象上的注解。
What are Java Annotations?
注解是Java5增加的功能。注解是一种注释或者是元数据可以直接插入到Java代码中。在编译时,通过预编译工具处理;或者在运行时,通过java反射处理。下面是个注解的例子:
1 | @MyAnnotation(name="someName", value = "Hello World") |
类TheClass的上面有个@MyAnnotation的注解。注解的定义类似接口定义,下面是注解定义的例子:
1 | @Retention(RetentionPolicy.RUNTIME) |
创建注解是,在interface前面使用@即可。创建之后就可以在代码里使用了,例如上面的例子。
@Retention(RetentionPolicy.RUNTIME) 和 @Target(ElementType.TYPE)这两个指令,指明了这个注解如何被使用。
@Retention(RetentionPolicy.RUNTIME) 意味着在运行时状态可以使用java反射获取注解,如果不设置这个指令,在运行时状态,注解不会被保存,同样的也就不能通过反射获取。
@Target(ElementType.TYPE)意味着注解只能用在Types上(比如类和接口)。你也可以指定为METHOD或者是FIELD,或者是不使用Target这个指令,这样你就可以在类,方法,变量上使用了。
Class Annotations
你可以在运行期访问类,方法,变量的注解。下面是类注解的例子:
1 | Class aClass = TheClass.class; |
也可以指定类进行访问,例如:
1 | Class aClass = TheClass.class; |
Method Annotations
下面是注解在方法上的例子:
1 | public class TheClass2 { |
可以像下面这样访问方法注解:
1 | Method method = TheClass2.class.getMethod("doSomething"); |
或者是指定方法注解:
1 | Method method = TheClass2.class.getMethod("doSomething"); |
Parameter Annotations
在方法的参数上使用注解:
1 | public class TheClass3 { |
访问方法参数上的注解:
1 | Method method = TheClass3.class.getMethod("doSomethingElse"); |
注意Method.getParameterAnnotations()返回的是二维数组,包含每个参数的注解数组。
Field Annotations
变量上的注解使用:
1 | public class TheClass4 { |
访问变量上的注解:
1 | Field field = TheClass4.class.getField("myField"); |
或者:
1 | Field field = TheClass4.class.getField("myField"); |
Java反射之私有变量和私有方法
通常情况下,从对象外部访问私有变量和私有方法是不被允许的,但是通过反射可以很容易获取私有变量和私有方法,在单元测试的时候很有用。
Accessing Private Fields
获取私有变量你需要用到Class.getDeclaredField(String name)或者Class.getDeclaredFields(String name)方法。Class.getField(String name)和Class.getFields(String name)方法只能返回公有变量。下面是通过java的反射获取私有变量代码:
1 | Order privateObject = new Order("2016051901"); |
这段代码会打印出『orderId:2016051901』,值为Order实例私有变量orderId的值。
Order.class.getDeclaredField("orderId")这个方法返回一个私有变量,这个私有变量是Order类中自己定义的变量,而不是继承自其父类的变量。
privateField.setAccessible(true);这个方法会关闭实例类的反射访问检查。现在你可以访问私有的,受保护的和包级访问的变量。
Accessing Private Methods
要获取私有方法你需要使用方法Class.getDeclaredMethod(String name, Class[] parameterTypes)或者Class.getDeclaredMethods()。Class.getMethod()和Class.getMethods()方法只是返回的公有方法。下面是使用java反射访问私有方法的代码:
1 | Order privateObject = new Order("2016051901"); |
这段代码会打印出『returnValue=2016051901』,其值是通过反射调用Order实例的私有方法『getOrderId()』获取到的。
Order.class.getDeclaredMethod("getOrderId"),这个方法也之后返回Order类自己的私有方法,而非其继承自父类的私有方法。
privateMethod.setAcessible(true),这个方法会关闭实例类的私有方法反射访问检查,现在你可以通过反射获取的实例的私有,受保护和包级访问权限的方法。
